Reconozcámoslo, normalmente en Javascript no nos preocupamos mucho de la memoria. En los navegadores el entorno de ejecución se reiniciará frecuentemente: cuando cambia el usuario de página en un navegador, cierra y abre las pestañas, etc. Pero cuando ejecutamos Javascript en Node, podemos tener un servicio corriendo durante días, meses e incluso años, sin que se reinicie el servicio. Algo parecido puede ocurrir en un quiosco desatendido, donde mostramos un contenido dinámico sin intervención del usuario y, donde de forma natural, no se recarga la página (aunque nosotros siempre podemos forzar esta recarga).
Cuando uno implementa un patrón memoize no suele preocuparse del tamaño de la caché que va generando. Por si alguno se ha olvidado, la memoificación es una técnica de optimización utilizada principalmente para acelerar las llamadas a funciones costosas, almacenando los resultados de las llamadas y devolviendo el resultado almacenado en caché cuando vuelven a llamarse con los mismos parámetros.
En estos casos, la ejecución ininterrumpida hace que la aparentemente inocente caché de la función memoize va creciendo y creciendo hasta ocupar tamaños absolutamente monstruosos, llegando incluso a producir errores de falta de memoria en el sistema. Por ejemplo, en este código forzamos a la ejecución constante de una función memoizada hasta el máximo de enteros soportados por el sistema. Aunque el comportamiento puede cambiar de un entorno a otro (Firefox, por ejemplo, hace un uso asombroso de la memoria), el resultado será que antes o después el sistema se quedará sin memoria disponible.
[code lang=»javascript»]
function memoize (fn) {
const caché = new Map ();
return function (arg) {
if (caché.has (arg)) {
return caché.get (arg);
}
const result = fn (arg);
caché.set (arg, result);
return result;
}
}
const sqrt = memoize (function sqrt (arg) {
return Math.sqrt (arg);
});
for (let n = 0; n < Number.MAX_SAFE_INTEGER; n++) {
sqrt (n);
}
[/code]
Con este ejemplo en Node, al superar 16.777.215 millones de elementos en el objeto Map, se produce este error catastrófico:
[code lang=»javascript»]
FATAL ERROR: invalid table size Allocation failed – JavaScript heap out of memory
1: 00007FF6B9AC592A v8::internal::GCIdleTimeHandler::GCIdleTimeHandler+4554
2: 00007FF6B9A76586 uv_loop_fork+83462
3: 00007FF6B9A7705E uv_loop_fork+86238
4: 00007FF6B9E5E49E v8::internal::FatalProcessOutOfMemory+798
5: 00007FF6B9E5E3D7 v8::internal::FatalProcessOutOfMemory+599
6: 00007FF6B9F091A4 v8::internal::Heap::RootIsImmortalImmovable+14068
7: 00007FF6BA0A6F92 v8::internal::BigIntLiteral+56658
8: 00007FF6BA0A75CD v8::internal::BigIntLiteral+58253
9: 00007FF6BA155594 v8::internal::StoreBuffer::StoreBufferOverflow+123924
10: 0000035C78B50481
[/code]
Debemos tener claro que no se ha producido un memory leak, es decir, no se ha perdido memoria de forma inadecuada, lo que ha ocurrido es que hemos ido almacenando datos y consumido la memoria necesaria para almacenar esos datos y, aunque el compilador pueda gestionar eficientemente esta memoria, por ejemplo, enviando a disco los datos no utilizados, ha sido nuestro código el que ha hecho una absolutamente desmedida acumulación de memoria.
Limitar el tamaño de Map
Una primera idea puede ser crear nuestra propia clase que herede de Map y añadir un límite de elementos. Una vez sobrepasado este límite, no se pueden introducir nuevos datos y se lanza un error, que se puede capturar, no como los errores catastróficos por falta de memoria.
[code lang=»javascript»]
const LIMIT = Symbol ();
class LimitedMap extends Map {
constructor (iterator, limit) {
if (typeof iterator === ‘number’) {
limit = iterator;
iterator = undefined;
}
super (iterator);
this[ LIMIT ] = limit;
}
set (key, value) {
if (this.size >= this[ LIMIT ] ) {
throw new Error (‘Limit exceeded’)
}
return super.set (key, value)
}
}
[/code]
La verdad es que no es muy complicado, hemos añadido un nuevo parámetro limit al constructor y hemos sobreescrito el método .set() para que compruebe si se ha superado el límite de elementos. En caso de que se haya superado, entonces se lanza un error, que podemos capturar en nuestro programa.
Una característica interesante es que la nueva clase funciona tanto si le ponemos un límite:
[code lang=»javascript»]
// Limited
const s = new LimitedMap (10);
s.set (‘a’, 1);
s.set (‘b’, 2);
s.set (‘c’, 3);
s.set (‘d’, 4);
s.set (‘e’, 5);
s.set (‘f’, 6);
s.set (‘g’, 7);
s.set (‘h’, 8);
s.set (‘l’, 9);
s.set (‘m’, 10);
s.set (‘n’, 11); // Throw an error
[/code]
como si no lo hacemos:
[code lang=»javascript»]
// Non limited
const m = new LimitedMap ();
for (let i = 0; i < 100; i++) {
m.set (i, Math.random ());
}
[/code]
Aunque esto parece prometedor, lo cierto es que no es muy práctico, ya que una vez superado el límite de elementos se produce un molesto error, que deberíamos capturar y no está muy claro que podríamos hacer a partir de ese momento. Quizás podríamos borrar elementos del Map y volver a intentar la ejecución, pero hacer esto desde la función memoize() parece poco elegante. Veamos algunas alternativas.
LimitedMap como clase abstracta
Como ejercicio de exploración, vamos a separar las responsabilidades, primero haciendo de LimitedMap una clase abstracta, es decir, que no vamos a aceptar que se creen instancias directamente de esta clase. Para poder utilizar esta clase tenemos que heredar de ella e implementar un método .eraser() de borrado de elementos.
[code lang=»javascript»]
const ERROR_ABSTRACT = ‘This is an abstract class.’;
const ERROR_LIMIT = ‘Limit exceeded and "eraser()" is not implemented.’;
const LIMIT = Symbol ();
const ERASER = Symbol ();
class LimitedMap extends Map {
constructor (iterator, limit) {
if (new.target === LimitedMap) {
throw new Error (ERROR_ABSTRACT);
}
if (typeof iterator === ‘number’) {
limit = iterator;
iterator = undefined;
}
super (iterator);
this[ LIMIT ] = limit;
this[ ERASER ] ();
}
get limit () {
return this [ LIMIT ];
}
set (key, value) {
this[ ERASER ] ();
return super.set (key, value)
}
[ ERASER ] () {
if (this.size > this[ LIMIT ]) {
if (this.eraser) {
while (this.size > this[ LIMIT ]) {
this.eraser ();
}
} else {
throw new Error (ERROR_LIMIT)
}
}
}
}
[/code]
Ahora, si intentamos usar directamente la clase, nos lanzará un error:
[code lang=»javascript»]
const s = new LimitedMap (10);
console.log (s.limit);
[/code]
Pero sí podemos utilizar una clase heredada, aunque no implemente el método .erarser():
[code lang=»javascript»]
const s = new (class extends LimitedMap {}) (10);
console.log (s.limit);
[/code]
Hemos escrito algunas líneas en el método [ ERASER ]() para asegurarnos que la clase hija implementa el método .eraser() antes de llamarlo, aunque algunos consideren que esta es una sobreprotección y que las clases hijas deben ser responsables de implementar este método o se atañen a las consecuencias. Este método lo llamamos desde .set() y desde el constructor, ya que si se han creado elementos pasando un iterador al constructor, tenemos que comprobar que el tamaño es el adecuado.
Existen muchas estrategias de borrados de elementos de la caché, por lo que vamos a hacer una serie de clases que heredando de LimitedMap implementen alguna de estas posibles criterios para borrar elementos.
CircularMap borra los registros incorporados al inicio
Ahora vamos a implementamos la clase CircularMap con la primera estrategia de borrado de elementos. Para ello hemos heredado en LimitedMap, que a su vez hereda de Map.
La estrategia es bien sencilla, cuando se llega al límite de elementos se elimina el que se insertó primero en el objeto. Este es un criterio razonable cuando no existen unos parámetros más frecuentes que otros o no es relevante si se utilizó hace menos o más tiempo. Simplemente se borrar por el principio y se añaden valores por el final, por eso le hemos llamado circular.
[code lang=»javascript»]
class CircularMap extends LimitedMap {
eraser () {
this.delete (this.keys ().next ().value);
}
}
[/code]
Para borrar los elementos hemos hecho uso de un pequeño truco, que es llamar a this.keys () que devuelve un iterador y por lo tanto tiene un método .next() que devolverá el primer elemento que podemos obtener con la propiedad .value. Ahora que tenemos la clave del primer elemento, y hemos evitado tener que recorrernos todos los elementos del objeto, ya podemos borrarla con un simple this.delete().
Veamos cómo funcionaría en la práctica:
[code lang=»javascript»]
const s = new CircularMap (10);
s.set (‘a’, 1);
s.set (‘b’, 2);
s.set (‘c’, 3);
s.set (‘d’, 4);
s.set (‘e’, 5);
s.set (‘f’, 6);
s.set (‘g’, 7);
s.set (‘h’, 8);
s.set (‘l’, 9);
s.set (‘m’, 10);
s.set (‘n’, 11); // remove the first element
console.assert (!s.has (‘a’));
console.assert (s.has (‘n’));
[/code]
LimitedMap borra los registros incorporados al final
En este caso vamos a hacer lo contrario, borraremos el último valor que se han incluido en el objeto cuando lleguemos al límite establecido.
[code lang=»javascript»]
class LastMap extends LimitedMap {
eraser () {
this.delete( […this.keys()][ this.size – 1 ] );
}
}
[/code]
Veamos cómo funcionaría en la práctica:
[code lang=»javascript»]
const s = new LastMap (10);
s.set (‘a’, 1);
s.set (‘b’, 2);
s.set (‘c’, 3);
s.set (‘d’, 4);
s.set (‘e’, 5);
s.set (‘f’, 6);
s.set (‘g’, 7);
s.set (‘h’, 8);
s.set (‘l’, 9);
s.set (‘m’, 10);
s.set (‘n’, 11); // remove the last element
console.assert (!s.has (‘m’));
console.assert (s.has (‘n’));
[/code]
Quizás no nos hemos dado cuenta, pero estamos borrando siempre un único elemento y volvemos a insertar otro en el último lugar, por lo no estamos haciendo algo muy inteligente, ya que prácticamente todos los datos menos uno -que cambia continuamente- se mantienen en el objeto. La solución pudiera ser borrar un mayor número de datos, pero en general borrar del mismo lado que insertamos no es muy coherente. Bueno, al menos nos sirve de ejemplo sobre lo que podemos hacer.
RecentMap borra los elementos utilizados hace más tiempo
Para esta estrategia lo primero que tenemos que aclarar es que significa utilizado. Básicamente consideramos que un elemento es utilizado cuando se crea, se actualiza (ambos con el método .set()) o se consulta (con el método .get()). Quizás en otros contextos se podría formular de forma diferente este criterio.
La idea es borrar los elementos que hemos actualizado o accedido hace más tiempo, manteniendo los más recientemente utilizados. Este es un criterio bastante práctico en algunos casos, donde los parámetros se van actualizando con el paso del tiempo y lo más antiguos dejan de ser relevantes.
[code lang=»javascript»]
const RECENCY = Symbol ();
const update = (function () {
let n = 0;
return function () {
return ++n;
}
}) ();
class RecentMap extends LimitedMap {
constructor (array, limit) {
super (array, limit);
this[ RECENCY ] = this[ RECENCY ] || new SortedMap ();
}
set (key, value) {
this[ RECENCY ] = this[ RECENCY ] || new SortedMap ();
const result = super.set (key, value);
this[ RECENCY ].set (key, update ());
return result;
}
get (key) {
const result = super.get (key);
this[ RECENCY ].set (key, update ());
return result;
}
eraser () {
const removeSize = Math.floor(this.size * 0.05);
for (let n = 0; n < removeSize; n++) {
const key = this[ RECENCY ].keys ()[ 0 ];
this.delete (key);
this[ RECENCY ].delete (key);
}
}
}
[/code]
Vamos a explicar este código paso a paso:
- Hemos creado un símbolo
RECENCYque vamos a utilizar para referenciar de forma oculta un Map ordenado con la claseSortedMap, tal y como vimos en el artículo anterior. - La función
update()se utiliza para obtener un contador único, de esta forma podemos saber que acceso se ha realizado antes y cual después. Podríamos haber usado una función de tiempo de alta precisión, pero ese sistema es sencillo y funciona. - En los métodos
.set()y.get()se llama la funciónupdate()y se guarda el valor enthis[ RECENCY ]. - A la hora de borrar, se van a eliminar el 5% de los datos contenidos en el objeto, para ello se obtiene el elemento más bajo del objeto
SortedMapque hay enthis[ RECENCY ]y se borra hasta eliminar el número deseado de elementos. Borrar un porcentaje de los datos puede mejorar el tiempo de respuesta, pero no siempre es buena idea. Lo dejamos aquí para mostrar cómo se implementaría.
Veamos cómo funcionaría en la práctica:
[code lang=»javascript»]
const s = new RecentMap (10);
s.set (‘a’, 1); // used by set
s.set (‘b’, 2);
s.set (‘c’, 3);
s.set (‘d’, 4);
s.set (‘e’, 5);
s.set (‘f’, 6);
s.set (‘g’, 7);
s.set (‘h’, 8);
s.set (‘l’, 9);
s.set (‘m’, 10);
s.get (‘a’); // used by get
s.get (‘b’);
s.get (‘c’);
s.set (‘n’, 11); // delete the item used longer
console.assert (s.has (‘a’));
console.assert (!s.has (‘d’));
[/code]
FrequentMap borra los elementos menos utilizados
En este caso consideramos que utilizado significa lo mismo que en el caso anterior, es decir, que un elemento es utilizado cuando se crea, se actualiza su valor (ambos con el método .set()) o se consulta (con el método .get()).
La idea es borrar los elementos que hemos utilizado menos veces, manteniendo aquellos que hemos utilizado en más ocasiones. Este es un criterio muy interesante en muchos de los casos, ya que mantiene en la caché los casos más habituales y será especialmente eficiente si existen algunos casos más frecuentes que otros.
[code lang=»javascript»]
const FREQUENCY = Symbol ();
class FrequentMap extends LimitedMap {
constructor (array, limit) {
super (array, limit);
this[ FREQUENCY ] = this[ FREQUENCY ] || new SortedMap ();
}
set (key, value) {
const result = super.set (key, value);
this[ FREQUENCY ] = this[ FREQUENCY ] || new SortedMap ();
this[ FREQUENCY ].set (key, (this[ FREQUENCY ].get (key) || 0) + 1);
return result;
}
get (key) {
const result = super.get (key);
this[ FREQUENCY ].set (key, this[ FREQUENCY ].get (key) + 1);
return result;
}
eraser () {
const key = this[ FREQUENCY ].keys ()[ 0 ];
this.delete (key);
this[ FREQUENCY ].delete (key);
}
}
[/code]
Vamos a explicar que hemos hecho en este caso:
- Hemos creado un símbolo
FREQUENCYque vamos a utilizar para referenciar de forma oculta un objetoSortedMap. - En los métodos
.set()y.get()se les actualiza el valor guardadothis[ FRECUENCY ]sumando 1 al valor existente. De esta forma vamos contando las veces que usamos cada clave. - A la hora de borrar, se elimina el elemento menos utilizados y que está ordenado en el objeto
SortedMapque hay enthis[ FRECUENCY ].
Veamos cómo funcionaría en la práctica:
[code lang=»javascript»]
onst s = new FrequentMap (5);
s.set (‘a’, 1);
s.set (‘b’, 2);
s.set (‘c’, 3);
s.set (‘d’, 4);
s.set (‘e’, 5);
s.get (‘a’);
s.get (‘b’);
s.get (‘c’);
s.get (‘d’);
s.set (‘f’, 6); // remove least used element
console.assert (s.has (‘a’));
console.assert (!s.has (‘e’));
[/code]
Algunas anotaciones sobre el rendimiento
En primer lugar, advertir que estos ejemplos son sólo de carácter didáctico y no se pretende que sean utilizados en producción sin haberlos pulido y mejorado. Sólo intentan mostrar lo que se puede hacer para gestionar una caché limitada heredando del objeto Map.
En segundo lugar, limitar el tamaño de la caché limita también su efectividad ya que va a encontrarse casos que se han eliminado y por lo tanto tiene que volver a llamar a la función costosa. Definir un tamaño más o menos pequeño o grande para la caché hace que cambie de forma muy significativa su efectividad y por lo tanto tendremos que ajustar a cada caso de uso para mantener un adecuado equilibrio entre uso de memoria y rendimiento.
En tercer lugar, el criterio de eliminación de elementos de la caché depende de la naturaleza de los datos que vamos a utilizar. No es posible dar un criterio general. Habrá casos donde la frecuencia de uso sea un criterio interesante, sobre todo cuando se produce un cierto sesgo, es decir, hay unos parámetros que con el tiempo se utilizan más que otros. En otros casos la antigüedad de los datos será más relevante, ya que estos cambian con el tiempo y es más interesante conservar los más recientes y despreciar los más antiguos. En otros casos no podremos establecer un criterio y borrar datos de forma circular, es decir, borrar datos por un extremo de la pila y añadirlos por el otro, sea suficientemente efectivo al no poder identificar otro criterio mejor.
Para poder mostrar las diferencias de rendimiento hemos preparado un caso de prueba particular. Para ello vamos a utiliza una función bastante costosa (entre 36 y 42 milisegundos por cada llamada) que busca el código postal de una dirección con una aproximación fonética. Hemos seleccionado 3.000 direcciones al azar y sin orden alguno, donde 20 de ellas se repiten entre 40 y 20 veces, 200 se repiten entre 2 y 20 veces, 380 se repiten 2 veces y el resto sólo aparecen una vez, como resultado hay 1.000 direcciones diferentes. Las veces que se repiten las llamas es fundamental para conocer la eficiencia de una caché, cuantas más veces se repitan las llamadas con los mismos parámetros más veces se podrán utilizar los datos almacenados en la caché y menos veces habrá que llamar a la función original.
Antes de continuar, se nos olvidaba, esta es la versión de la función memoize a la que podemos pasar un objeto heredado de LimitedMap para que gestione su caché con un límite de tamaño:
[code lang=»javascript»]
function memoize (fn, caché) {
if (!caché) {
caché = new Map();
}
return function (arg) {
if (caché.has (arg)) {
return caché.get (arg);
}
const result = fn (arg);
caché.set (arg, result);
return result;
}
}
[/code]
Ahora podemos utilizarla de esta forma:
[code lang=»javascript»]
const caché = new FrequentMap(500);
const searchCPM = memoize (searchCP, caché);
[/code]
Los tiempos medios (por cada 100 llamadas) a la función sin memoize, a la función con una una caché ilimitada con Map y a las funciones con caché limitadas a 500 elementos con CircularMap y FrequentMap son los siguientes:
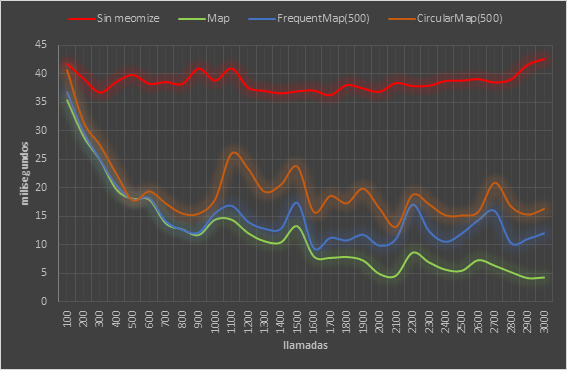
- Como podemos ver la llamada sin memoize mantiene los tiempos más o menos homogéneos entre los 36 y 42 milisegundos de media.
- Todas las versiones con caché van mejorando sus tiempos de respuesta en cuanto van calentando la caché, es decir, en cuanto van teniendo datos a los que pueden responder sin necesidad de llamar a la función original. Las variaciones en los tiempos de respuesta están producidas por el orden aleatorio en las llamadas y hay tramos con más llamadas en caché que otros.
- Cuando no limitamos la caché los tiempos van mejorando cada vez más, ya que al no tener límite cualquier llamada es cachéada. Esta es la mejor opción siempre que podamos utilizarla.
- De las versiones con caché limitada la que mejor que se comporta es
FrequentMap, ya que nuestro caso repite bastantes casos y el criterio de borrado por frencuencia de uso ayuda. - En cualquier caso el comportamiento de
CircularMapno es malo, pero al borrar elementos sin criterio alguno, termina siendo algo menos eficiente.
Conclusiones
Es posible que no sea de de aplicación directa en tus proyectos el uso de funciones con memoize, quizás no sea de aplicación el uso de objetos Map limitados en tamaño, pero estamos seguros que este tipo de soluciones puedes adaptarlos a casos de uso relevantes para tu trabajo. Conocer estas técnicas te puede servir en muchas más ocasiones de las que inicialmente hubieras pensado.
Como ya hemos comentado, no pretendemos que estos ejemplos sean utilizados directamente en producción. Son sólo estrategias en los que poderse basar para descubrir nuevas vías de adaptación y optimización a las necesidades concretas que tengas en tu proyecto. Por ejemplo, siguiendo esta senda se pueden desarrollar cachés basadas en Map con fecha y hora de caducidad, es decir, que los datos queden invalidados cuando ha pasado un tiempo determinado, tras el que tendríamos que volver a llamar a la función original. Las posibilidades son muy amplias y os animamos a explorarlas.
Novedades

HTTP2 para programadores. Enviar mensajes del servidor al cliente con Server Sent Event (sin WebSockets)
En esta charla, organizada por MadridJS, Pablo Almunia nos muestra cómo la mayoría de nosotros cuando oímos hablar por primera vez de HTTP2 nos ilusionamos con las posibilidades que presumiblemente se abrían para el desarrollo de soluciones web avanzadas y cómo muchos nos sentimos defraudados con lo que realmente se podía implementar.
En esta charla podemos ver cómo funciona el HTTP2, que debemos tener en cuenta en el servidor para hace uso de este protocolo y, sobre todo, cómo podemos enviar información desde el servidor al cliente de forma efectiva y fácil. Veremos con detenimiento cómo por medio de los Server-Sent Events (SSE) podemos recibir en el cliente datos enviados desde el servidor sin utilizar websocket, simplificando enormemente la construcción de aplicaciones con comunicación bidireccional.

Observables en Javascript con Proxies
En esta charla, organizada por MadridJS, Pablo Almunia nos habla de la observación reactiva de objetos en Javascript por medio de Proxy. Se describe paso a paso cómo funcionan los Proxies y en que casos pueden ser nuestro mejor aliado. Veremos que no hay que tenerles miedo, son bastante sencillos de utilizar, y nos ofrecen una gran abanico de posibilidades.

Aplicaciones JAMStack, SEO friendly y escalables con NextJS
En esta charla de Madrid JS, Rafael Ventura nos describe las funcionalidades clave de NextJS, nos muestra en vivo cómo desarrollar una completa aplicación JAMStack con Server Side Rendering (SSR) y Static Site Generation (SSG) y termina mostrando como publicar esta aplicación en Vercel.

Stencil JS: mejora el Time To Market de tu producto, por Rubén Aguilera
En esta charla Rubén Aguilera nos cuenta los problemas que tienen muchas empresas a la hora de sacar productos accesibles, vistosos y usables en el Time To Market que requiere Negocio y cómo podemos minimizar este tiempo gracias al DevUI con StencilJS para adecuar una aplicación de Angular a las exigencias del mercado en tiempo record.