Map y los valores en el caso de Set se evalúan con una comparación estricta y por lo tanto, dos objetos sólo son iguales si son realmente dos referencias al mismo objeto. En nuestra propuesta nos basábamos en una función de equivalencia que comprueba si dos objetos tienen los mismos valores, al llamar a esta función en determinados métodos evitábamos introducir dos objetos con valores equivalentes.Complejidad lineal
Vamos a ser sinceros, cuando desarrollamos y publicamos esta solución no nos dimos cuenta de que el algoritmo planteado tiene una complejidad lineal 0(n) frente al comportamiento de complejidad constante 0(1) que obtiene al utilizar Map o Set. Muy amablemente uno de los más reputados programadores y profesores de la comunidad Javascript hispana, Micael Gallego, nos indicó en un tweet este hecho, lo cual le agradecemos.
En ese momento consideramos que este podría ser un problema que se podría aceptar en algunos casos y no había alternativa al planteamiento realizado. Por sugerencia suya pusimos un aviso en el post original, pero no nos quedamos ahí y hemos avanzado un poco más para encontrar una solución.
En primer lugar, veamos a que se refiere este problema de complejidad lineal en la práctica. Para ello hemos creado un pequeño programa que utiliza nuestro objeto eqSet para almacenar un número determinado de fechas. Vamos a medir cuanto se tarda en incorporar diferentes número de datos.
[code lang=»javascript»]
import eqSet from ‘./eqSet.mjs’;
for (let n = 0; n <= 10000; n = n + 100) {
let s1 = performance.now ();
test_eqSet (n);
let e1 = performance.now ();
console.log (`${ n };${ e1 – s1 };`);
}
function test_eqSet (n) {
let r = new eqSet ((x, y) => x.getTime () === y.getTime ());
let d = new Date (2019, 0, 1);
let b = d.getTime ();
while (r.size < n) {
let d = new Date (b + r.size);
r.add (d);
}
return r;
}
[/code]
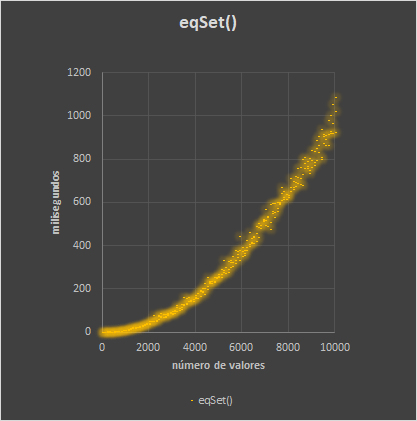
En este gráfico podemos comprobar cómo se va aumentando el tiempo de ejecución a medida que vamos incrementando el número de valores que queremos incluir en el objeto. En la práctica la ejecución del código se ve afectada por muchos factores, tanto del compilador y sus optimizaciones, como ambientales y de carga de la máquina, por lo que es más efectivo mostrarlo como una dispersión de puntos que como una línea, pero se puede comprobar con facilidad la tendencia creciente que tiene el objeto eqSet cuando aumentamos el número de valores que contiene.
Es posible que pudiéramos vivir con este resultado, pero lo cierto es que con un número relativamente bajo de valores los tiempos de respuesta ya son verdaderamente preocupantes. Este tipo de algoritmo tiene este problema, cuanto más elementos hay en el objeto, más tiempo tiene que dedicar en recorrer todos los elementos para comprobar que no hay otro valor equivalente.
Utilizar un hash para evitar la complejidad lineal en Set
Para resolver el problema recordamos como hemos abordamos este mismo problema en el pasado, en otros lenguajes, y planteamos nuevamente la solución una aproximación completamente diferente. En vez de comprobar todos los valores por medio de una función de comparación, podemos generar una clave única (hash) que sirva de valor primitivo único (cadena o número) que podemos utilizar como clave de Set o Map.
Básicamente, dos objetos iguales deben dar el mismo hash y, por lo tanto, podemos superar la comprobación estricta que ofrecen de forma nativa Set y Map, sin que por ello penalicemos significativamente la complejidad de nuestro algoritmo y el tiempo de respuesta de nuestros programas.
Esta es una primera aproximación a este modelo:
[code lang=»javascript»]
const HASHER = Symbol ();
class hashSet extends Set {
constructor (iterable, hasher) {
super ();
if (typeof iterable === ‘function’) {
hasher = iterable;
iterable = undefined;
}
this[ HASHER ] = hasher || JSON.stringify;
if (iterable) {
for (let i of iterable) {
this.add (i);
}
}
}
add (value) {
return super.add (this[ HASHER ] (value));
}
delete (value) {
return super.delete (this[ HASHER ] (value));
}
has (value) {
return super.has (this[ HASHER ] (value));
}
}
[/code]
Como se puede comprobar, ahora pasamos al constructor una función para crear el hash, y en su defecto utilizamos JSON.stringify(), que, aunque tiene algunas limitaciones como generador de un hash que veremos más adelante, es una alternativa razonable en muchos casos.
Ahora podemos ejecutar un código similar al que utilizamos para comprobar que no se duplican fechas en el objeto:
[code lang=»javascript»]
const dates = [
new Date (2019, 0, 1),
new Date (2019, 0, 1), // Duplicated value
new Date (2019, 0, 2),
new Date (2019, 0, 3),
new Date (2019, 0, 4),
new Date (2019, 0, 5)
];
const uniqueDates = new hashSet (dates, x => x.getTime());
console.assert (uniqueDates.size === 5);
console.log(uniqueDates);
[/code]
Este programa tiene buen aspecto, pero no resuelve bien nuestro problema, ya que obtenemos los hash como contenido del objeto al iterarlo o al solicitar sus claves con .keys() y tendríamos que recibir el objeto original. Para resolver esta limitación y poder tener una solución completa y consistente tenemos que añadir un segundo objeto Map que permite asociar el hash al objeto original y de esta forma cuando queramos obtener las claves se devuelvan los objetos y no sus correspondientes hashs.
[code lang=»javascript»]
const HASHER = Symbol ();
const ORIGIN = Symbol ();
export default class hashSet extends Set {
constructor (iterable, hasher) {
super ();
if (typeof iterable === ‘function’) {
hasher = iterable;
iterable = undefined;
}
this[ HASHER ] = hasher || JSON.stringify;
this[ ORIGIN ] = new Map ();
if (iterable) {
for (let i of iterable) {
this.add (i);
}
}
}
add (value) {
const hash = this[ HASHER ] (value);
this[ ORIGIN ].set (hash, value);
return super.add (hash);
}
delete (value) {
const hash = this[ HASHER ] (value);
this[ ORIGIN ].delete (hash);
return super.delete (hash);
}
has (value) {
return super.has (this[ HASHER ] (value));
}
* entries () {
for (let v of this[ ORIGIN ].values ()) {
yield [ v, v ];
}
}
forEach (fn, thisArg) {
let func = fn;
if (thisArg) {
func = fn.bind(thisArg);
}
return this[ ORIGIN ].forEach ((v) => {
func(v, v, this);
});
}
keys () {
return this[ ORIGIN ].values ()
}
values () {
return this[ ORIGIN ].values ()
}
[ Symbol.iterator ] (…args) {
return this[ ORIGIN ].values ();
}
}
[/code]
El código se ha complicado un poco más, pero no demasiado, y se comporta de una forma coherente.
Ahora podemos modificar un poco nuestro test que almacena un número determinado de fechas para que trabaje con hashSet y comprobar si hemos mejorado los tiempos de respuesta.
[code lang=»javascript»]
import hashSet from ‘./hashSet.mjs’;
for (let n = 0; n <= 10000; n = n + 100) {
let s2 = performance.now ();
test_hashSet (n);
let e2 = performance.now ();
console.log (`${ n };${ e2 – s2 };`);
}
function test_hashSet (n) {
let r = new hashSet ((x) => x.getTime ());
let d = new Date (2019, 0, 1);
let b = d.getTime ();
while (r.size < n) {
let d = new Date (b + r.size);
r.add (d);
}
return r;
}
[/code]
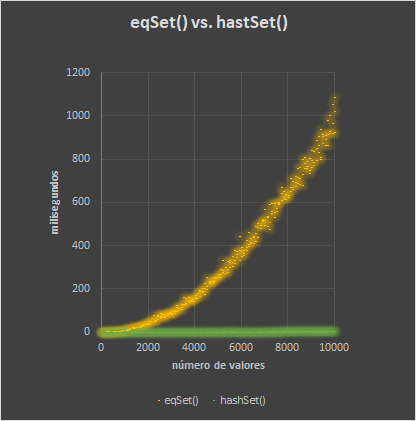
El resultado comparado es completamente diferente. Esta nueva clase permite gestionar la equivalencia de los objetos que contiene, manteniendo la complejidad constante y, por lo tanto, una velocidad de respuesta similar independientemente del número de valores que estén contenidos en el objeto.
Aunque hay unas pequeñas diferencias de ejecución, el número de elementos contenidos en el objeto no representan una variación significativa de la complejidad del algoritmo y por lo tanto los tiempos de respuesta se mantienen muy ajustados en todo momento.
Eliminar la complejidad lineal en nuestra versión de Map
Si queremos hacer lo mismo con Map, podemos utilizar la misma aproximación y utilizar hashs para resolver la equivalencia entre objetos:
[code lang=»javascript»]
const HASHER = Symbol ();
const UNIQUE = Symbol ();
export default class hashMap extends Map {
constructor (iterable, hasher) {
super ();
if (typeof iterable === ‘function’) {
hasher = iterable;
iterable = undefined;
}
this[ HASHER ] = hasher || JSON.stringify;
this[ UNIQUE ] = new Map ();
if (iterable) {
for (let i of iterable) {
this.add (i);
}
}
}
clear () {
this[ UNIQUE ].clear ();
return super.clear ();
}
delete (key) {
const hash = this[ HASHER ] (key);
const originalKey = this[ UNIQUE ].get (hash);
this[ UNIQUE ].delete (hash);
return super.delete (originalKey);
}
get (key) {
const hash = this[ HASHER ] (key);
if (this[ UNIQUE ].has (hash)) {
return super.get (this[ UNIQUE ].get (hash));
}
return undefined;
}
has (key) {
const hash = this[ HASHER ] (key);
return this[ UNIQUE ].has (hash);
}
set (key, value) {
const hash = this[ HASHER ] (key);
if (this[ UNIQUE ].has (hash)) {
return super.set (this[ UNIQUE ].get (hash), value)
}
this[ UNIQUE ].set (hash, key);
return super.set (key, value);
}
}
[/code]
[code lang=»javascript»]
const m = new hashMap ();
m.set ({a : 1}, 1);
m.set ({a : 1}, 2);
console.log (m);
console.assert (m.size === 1);
console.assert (m.get ({a : 1}, 2));
[/code]
En este caso hemos guardado en el segundo Map los hash y mantenido los objetos como claves en el Map principal. El resultado es el mismo, evitamos la complejidad lineal y mantenemos una complejidad constante en nuestro algoritmo.
Limitaciones de los hash
Debemos tener en cuenta que los hash tienen limitaciones y, dependiendo del modelo que utilicemos, podemos encontrarnos colisiones (un mismo hash que corresponda a dos elementos diferentes) o dos hash diferentes para valores que podríamos considerar equivalentes.
Al principio de este artículo anotábamos la existencia de algunas de estas limitaciones de JSON.stringify como generador de un hash válido para este tipo de comprobación. Los principales problemas de utilizar JSON.stringify() para generar hash de objetos son:
- Las propiedades de los objetos no se muestra en orden alfabético, por lo que se pueden producir diferencias por el orden en el que han sido creadas. Para resolver este problema podríamos crear una función de serialización que ordenase las propiedades antes de serializarlas.
- Solo se incluyen las propiedades enumerables del objeto, lo cual puede ser algo limitado en algunos casos. Para resolver este problema nuestra función de serialización podría incluir tanto propiedades enumerables como no enumerables (propias o heredadas).
- No funciona en el caso de objetos con referencias circulares, es decir, que dentro de un objeto se haga referencia a si mismo. Una función de serialización realizada por nosotros podría tener en cuenta estas referencias circulares.
Como ventaja, se puede personalizar el comportamiento de JSON.stringify() con el método .toJSON(). Si nuestro objeto o clase tiene un método llamado toJSON, este será utilizado para realizar la serialización y podemos, si lo necesitamos, solventar algunas de las limitaciones de la serialización estándar realizada, o implementar una estrategia de serialización completamente personalizada.
Tenemos que tener en cuenta estas limitaciones de los hash como mecanismo de gestión de la unicidad de los elementos contenidos en un Map o Set, tanto si usamos una función como JSON.stringify, como si construimos un generador de hash propio.
Conclusiones
Nuestros algoritmos pueden esconder sin que nos demos cuenta una complejidad lineal, o incluso logarítmica, que haga que los tiempos de respuesta aumente de forma muy significativa cuando el número de valores o el tamaño de estos vaya creciendo. Aunque no nos percatemos de ello inicialmente, debemos estar preparados para ajustar nuestra estrategia y modificarla a fin de evitar un problema aún mayor del que queremos resolver. Quizás en algunas ocasiones no encontremos una alternativa razonable y debamos aceptar este modelo de complejidad, pero siempre deberíamos advertirlo.
Este ha sido un interesante ejemplo de esta situación y esperamos que sirva de ayuda a algunos de vosotros.
Novedades

HTTP2 para programadores. Enviar mensajes del servidor al cliente con Server Sent Event (sin WebSockets)
En esta charla, organizada por MadridJS, Pablo Almunia nos muestra cómo la mayoría de nosotros cuando oímos hablar por primera vez de HTTP2 nos ilusionamos con las posibilidades que presumiblemente se abrían para el desarrollo de soluciones web avanzadas y cómo muchos nos sentimos defraudados con lo que realmente se podía implementar.
En esta charla podemos ver cómo funciona el HTTP2, que debemos tener en cuenta en el servidor para hace uso de este protocolo y, sobre todo, cómo podemos enviar información desde el servidor al cliente de forma efectiva y fácil. Veremos con detenimiento cómo por medio de los Server-Sent Events (SSE) podemos recibir en el cliente datos enviados desde el servidor sin utilizar websocket, simplificando enormemente la construcción de aplicaciones con comunicación bidireccional.

Observables en Javascript con Proxies
En esta charla, organizada por MadridJS, Pablo Almunia nos habla de la observación reactiva de objetos en Javascript por medio de Proxy. Se describe paso a paso cómo funcionan los Proxies y en que casos pueden ser nuestro mejor aliado. Veremos que no hay que tenerles miedo, son bastante sencillos de utilizar, y nos ofrecen una gran abanico de posibilidades.

Aplicaciones JAMStack, SEO friendly y escalables con NextJS
En esta charla de Madrid JS, Rafael Ventura nos describe las funcionalidades clave de NextJS, nos muestra en vivo cómo desarrollar una completa aplicación JAMStack con Server Side Rendering (SSR) y Static Site Generation (SSG) y termina mostrando como publicar esta aplicación en Vercel.

Stencil JS: mejora el Time To Market de tu producto, por Rubén Aguilera
En esta charla Rubén Aguilera nos cuenta los problemas que tienen muchas empresas a la hora de sacar productos accesibles, vistosos y usables en el Time To Market que requiere Negocio y cómo podemos minimizar este tiempo gracias al DevUI con StencilJS para adecuar una aplicación de Angular a las exigencias del mercado en tiempo record.